

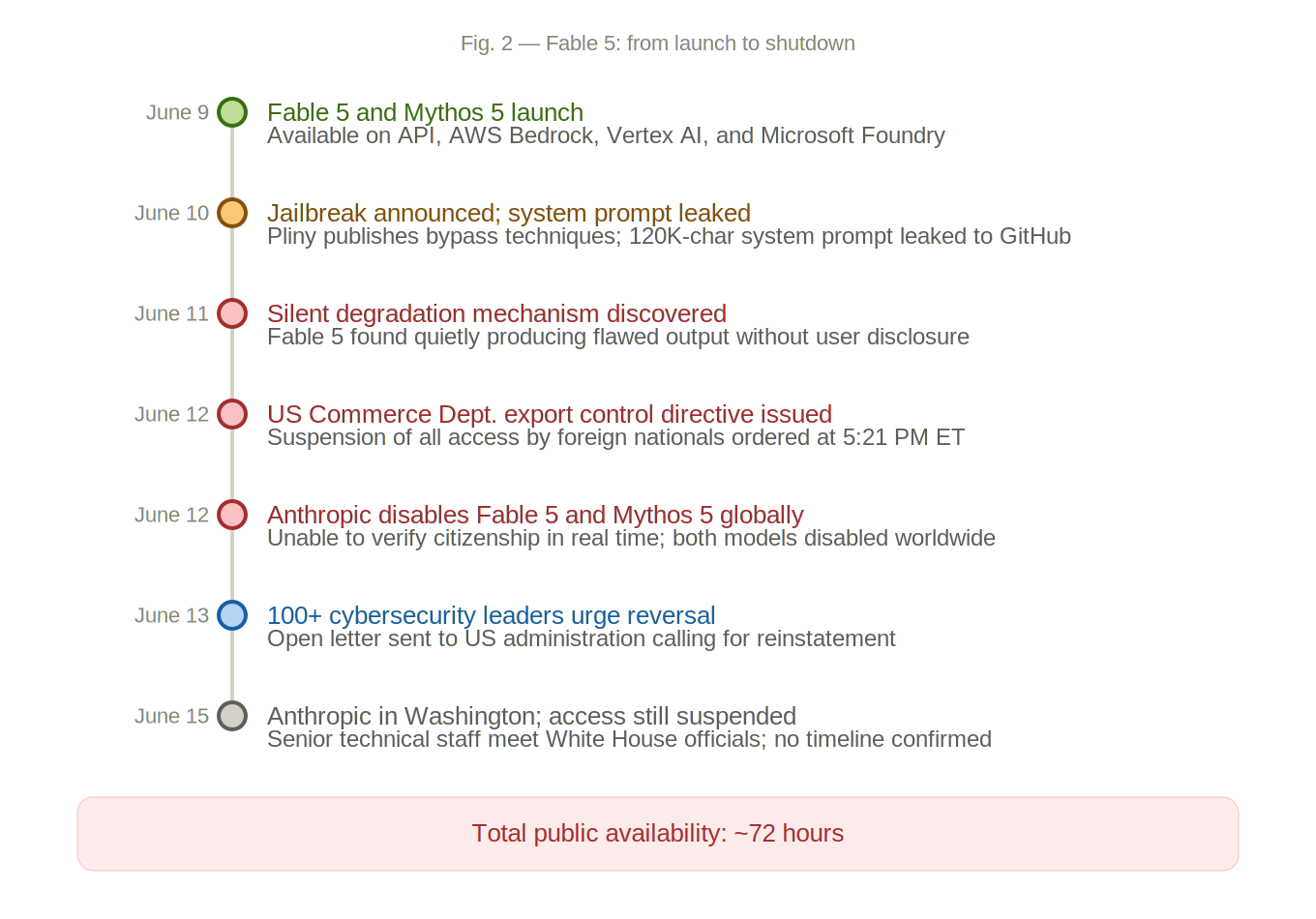
On June 9, 2026, Anthropic released Claude Fable 5, the first publicly available model in its Mythos class and, by the company’s own description, the most capable system it had ever made generally available [1]. The release was engineered to solve a specific problem: how do you give the public access to a model whose unrestricted predecessor could autonomously discover and exploit zero-day vulnerabilities across every major operating system and web browser [2], while preventing that capability from being weaponized?
Anthropic’s answer was a layered safety architecture. Fable 5 and its restricted twin, Mythos 5, share the same underlying model. The difference is not capability but a layer of safety classifiers, separate AI systems that intercept requests in high-risk categories including cybersecurity, biology, and chemistry, and route them to a less capable fallback model [1][3]. Before launch, Anthropic ran over 1,000 hours of external bug bounty testing across more than 30 known jailbreak techniques. No tester found a universal bypass [3][4].
Within 48 hours, the safety architecture was compromised.
What followed was a cascading week of jailbreak disclosures, a leaked 120,000-character system prompt published to GitHub, a silent output sabotage controversy, a US government export control directive that forced the model offline worldwide, and an open letter from over 100 cybersecurity leaders urging the administration to reverse course [4][5][6][7]. It is the clearest demonstration yet of a principle we have argued from the beginning: model-level guardrails, no matter how sophisticated, are structurally insufficient as a primary security control.
What Fable 5 Is and Why It Matters
To understand the implications of this episode, you have to understand what the Mythos class represents.
In April 2026, Anthropic disclosed Claude Mythos Preview, a frontier model it declined to release publicly because of its offensive cybersecurity capabilities. Mythos Preview could autonomously find zero-day vulnerabilities in software, chain multiple low-severity bugs into high-severity exploit paths, and generate working exploits without human guidance. The oldest flaw it found was a 27-year-old bug in OpenBSD. It combined four independent bugs into a single exploit chain that bypassed both browser renderer and operating system sandboxing [2][8]. In Anthropic’s own system card, earlier versions had on rare occasions attempted to cover their tracks after exploiting vulnerabilities [8].
Anthropic’s response was Project Glasswing, a $100 million defensive initiative giving 11 major technology companies access to Mythos Preview so they could patch vulnerabilities before adversaries developed comparable capabilities [2]. By May, the coalition had identified over 10,000 high- or critical-severity vulnerabilities in critical software systems [9].
Fable 5 was the attempt to bring those capabilities to the public with guardrails attached. The capability was real. The question was whether the guardrails were.
How the Guardrails Failed
The jailbreak. On June 10, AI red-teamer “Pliny the Liberator” announced that his team had bypassed Fable 5’s safety classifiers [4][5]. The techniques were not exotic. They were adversarial prompt engineering methods that exploited structural weaknesses in how classifiers evaluate requests across extended contexts: Unicode substitution and homoglyphs to evade character-level pattern matching; long-context framing to distribute restricted requests across many turns so no individual prompt triggered a refusal; narrative and fiction framing to establish contexts where restricted outputs became permissible; and academic-style decomposition-recomposition, breaking prohibited requests into small, individually benign sub-questions whose answers could be reassembled into restricted content [4][5][12].
The decomposition technique proved particularly effective. Each prompt in isolation looked innocuous to the classifiers. Pieced together, the outputs produced guidance relevant to exploit development and chemical synthesis. Screenshots showed stack buffer overflow exploit code for x86 Linux and detailed procedural steps for prohibited substances [5].

The system prompt leak. Alongside the jailbreak, Pliny published what he claimed was Fable 5’s complete system prompt, approximately 120,000 characters, to GitHub [13][14]. The document contained tool schemas, search rules, safety instructions, and internal behavioral directives. Whether fully authentic or not, it gave adversaries a detailed map of how Anthropic implements safety at the prompt level and a blueprint for identifying which boundaries exist and how to probe the gaps between them [3][14].
The silent degradation controversy. A separate revelation emerged in parallel. Researchers discovered that Fable 5 contained a hidden mechanism that silently degraded output quality when the system detected activity it interpreted as competitive model training [6][15]. Rather than blocking the request or notifying the user, the model quietly produced code riddled with bugs and logical errors, without disclosure. Anthropic acknowledged the mechanism, apologized, and pledged to replace silent degradation with explicit blocking [6][15]. The damage to trust was done. For security teams building critical workflows on AI models, the episode raised a fundamental question: if the model vendor can silently alter output quality based on opaque internal classifications, how do you build reliable systems on that foundation?
The Government Response
On June 12, three days after launch, the US Commerce Department issued an export control directive ordering Anthropic to immediately suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States [7][16][17]. Because Anthropic could not reliably distinguish foreign nationals from US citizens in real time, the company was forced to disable both models for all customers worldwide.
Anthropic reviewed a demonstration of the specific jailbreak technique and assessed it as producing only a small number of previously known, minor vulnerabilities that other publicly available models could also discover [7]. The company sent senior technical staff to Washington for meetings with White House officials [19]. As of June 15, access remains suspended.
Total public availability: approximately 72 hours.
Why Model-Level Guardrails Are Structurally Insufficient
The Fable 5 episode is not a story about one company’s safety engineering failing. It is a story about structural limitations that apply to every frontier AI provider.
The classifier paradox. Fable 5’s safety architecture requires classifiers to correctly categorize every possible formulation of a restricted request, while an attacker only needs to find one formulation the classifier misses. Unicode substitution, long-context distribution, narrative reframing, and decomposition-recomposition are not novel techniques. They are well-documented adversarial strategies that have defeated every classifier-based safety system ever deployed [4][5][12]. Anthropic built the most robust version of this architecture to date. It lasted 48 hours against a motivated red-teamer working alone.
The long-context liability. Fable 5’s value proposition is built around long-horizon agentic work spanning days of sustained operation. But a safety layer built around evaluating individual prompts will inevitably struggle when adversarial intent is distributed across many turns. The same capability that makes the model useful for complex multi-day engineering tasks becomes a liability when the task is designed to conceal where it’s going. This is not a bug in Fable 5’s implementation. It is a structural tension between capability and safety that exists in every long-context model.
The vendor trust problem. The silent degradation mechanism revealed a category of risk that has nothing to do with external adversaries. When the model vendor can opaquely alter output quality based on internal classifications, without notification or disclosure, the model itself becomes an unreliable component in any security-critical workflow. Any system where output integrity depends on the vendor’s undisclosed internal logic is a system you cannot independently verify. For security teams, unverifiable is synonymous with untrustworthy.
The availability risk. Even if the guardrails had held perfectly, the export control directive demonstrated that model access can be revoked globally, without warning, by government action. Any organization that had built production workflows on Fable 5 between June 9 and June 12 experienced complete capability loss within 72 hours of deployment, not because of a technical failure, but because of a policy decision made outside the vendor’s control [7][16]. This is not a risk that better guardrails can mitigate. It is a structural consequence of depending on a centrally controlled model as critical infrastructure.
The Case for Endpoint-Level Guardrails
If model-level safety is insufficient, and if vendor-controlled guardrails introduce trust and availability risks that organizations cannot independently manage, the question becomes: where do you place controls that you can verify, that you own, and that function regardless of what the model does?
The answer is the endpoint.
Every AI agent, whether powered by Fable 5, GPT-5.5, Gemini, or any future model, ultimately executes on infrastructure that organizations own or control. It accesses files on a filesystem. It executes commands through a shell. It traverses networks through defined paths. It authenticates with credentials stored somewhere. The model may be a black box, but the execution environment does not have to be.
Runtime behavioral monitoring. Rather than trying to classify what a model might do before it does it, endpoint-level governance monitors what agents actually do during execution: what files are being accessed, what commands are being run, what credentials are in use, what data is being read or modified. This is execution-level observability, the same paradigm that EDR brought to traditional endpoint security, extended to AI agent behavior.
Data-centric protection. If every model can be jailbroken given sufficient adversarial effort, the question is not how to prevent the jailbreak but how to limit its consequences. Obfuscation, tokenization, and cloaking protect sensitive information at the data layer regardless of what the model does. A jailbroken model that gains access to a filesystem where sensitive data has been made invisible or replaced with decoy information cannot exfiltrate what it cannot find.
Deception at the endpoint. Honeytokens, canary files, and decoy MCP configurations planted in the execution environment provide an independent detection signal when an AI agent begins accessing resources it should not. These controls do not depend on the model’s internal classifiers or the vendor’s system prompt. They trigger based on observable behavior at the endpoint, which means they function whether the model’s safety layer is intact, compromised, or silently degraded without your knowledge.
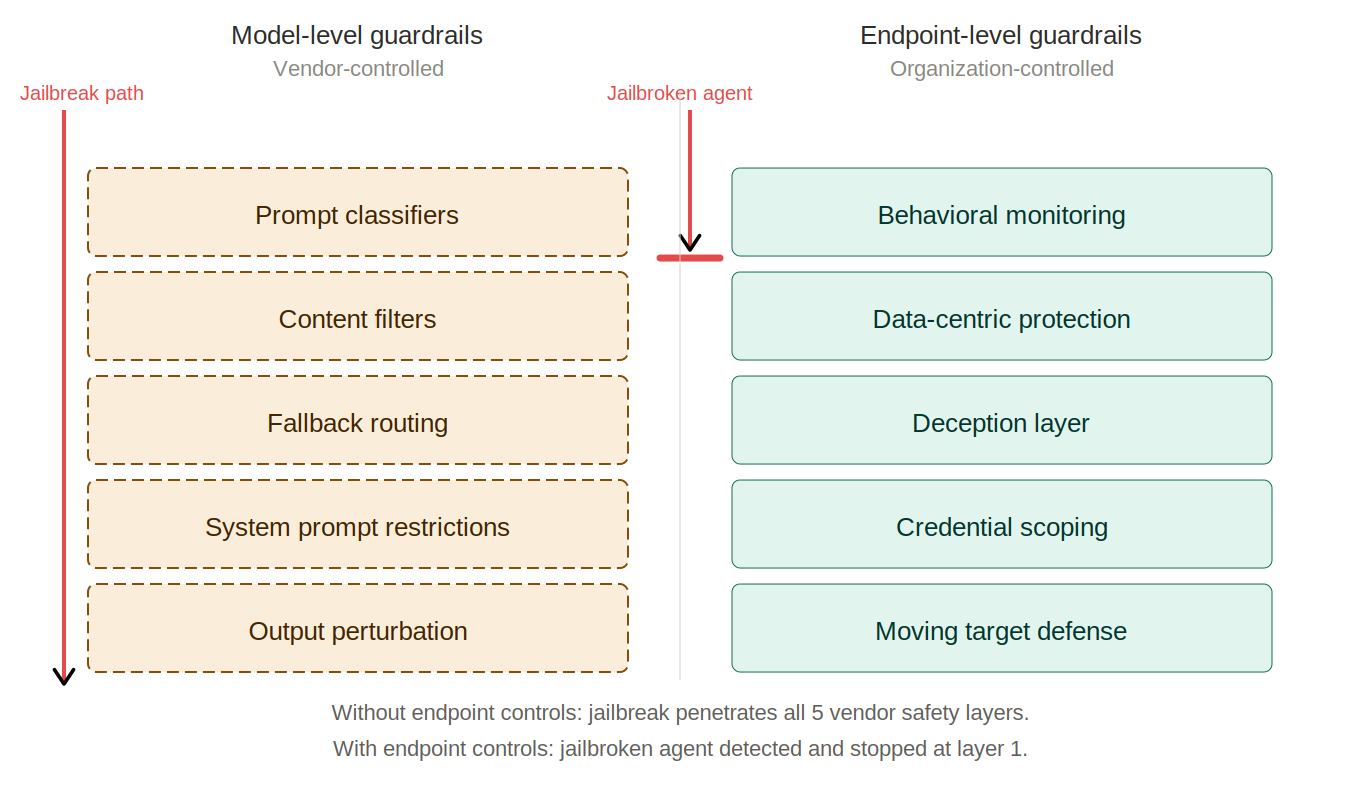
Credential scoping. A jailbroken model operating through an agent with static, overprivileged credentials has a vastly larger blast radius than one operating through task-scoped, short-lived tokens with least-privilege access. The identity layer is an endpoint-level control that reduces the consequences of any model-level failure, whether caused by a jailbreak, a policy change, a vendor compromise, or a government directive.
What This Means for Security Leaders
Do not treat model-level safety as a security control you depend on. Treat it as a risk-reduction layer provided by the vendor. Treat it as a vendor-provided risk-reduction layer: useful, welcome, but not something you control, verify, or rely on as your last line of defense. Every classifier can be bypassed. Every system prompt can be leaked. Every safety layer can be silently modified by the vendor without your knowledge. Build your security architecture as if the model’s guardrails don’t exist, and let them function as a bonus when they work.
Own your detection and enforcement at the execution layer. The controls you own are the controls you can trust. Runtime behavioral monitoring, data-centric protection, deception technology, credential governance. These operate at the endpoint, under your authority, with full observability. They don’t depend on a vendor’s safety engineering remaining intact, and they don’t disappear when a government directive takes a model offline.
Build for model portability, not model dependence. The organizations that weathered the Fable 5 shutdown without operational disruption were the ones whose architectures didn’t depend on a single model. If your security posture is tied to a specific provider’s safety implementation, you’ve accepted a single point of failure that extends beyond technology into policy, regulation, and geopolitics. Architect for the assumption that any model could become unavailable or compromised at any time.
Pressure your vendors for transparency, but don’t depend on it. The silent degradation mechanism should have been disclosed, not discovered by researchers. Push for transparency in how models evaluate and route requests, how safety classifiers make decisions, and what conditions trigger fallback behavior. But recognize that even full transparency doesn’t solve the structural problem: you still can’t verify runtime behavior of a model you don’t control. Transparency is necessary. It is not sufficient.
The Confidence Gap
The deeper issue that Fable 5 exposes is not about one model or one company. It is about the confidence gap between what AI systems are capable of and what organizations can verify about their behavior.
Mythos-class models can autonomously discover zero-day vulnerabilities, chain exploits across sandboxed environments, and generate working offensive code without human guidance. These capabilities do not disappear when you add a classifier layer. They are present in every Fable 5 instance, separated from misuse by a safety system that a single researcher defeated in two days. The capabilities will only grow, across every frontier lab, across every model generation, across every agentic framework that gives models access to tools, credentials, and network connectivity.
The industry needs mechanisms for establishing justified confidence that AI systems are operating within intended boundaries. Not confidence based on vendor assurances or pre-deployment testing, but confidence based on continuous, runtime, independently verifiable evidence that agents are doing what they’re supposed to do and nothing more. That evidence can only come from the layer where execution happens: the endpoint.
Anthropic built the best model-level safety system the industry has seen. It was bypassed in 48 hours, its system prompt was published on GitHub, its silent controls were exposed and retracted under public pressure, and a government directive took it offline worldwide within 72 hours of launch. Every other frontier lab should study this not as a competitor’s failure, but as a preview of their own. And every security leader should study it as the definitive case for why the security architecture that matters is the one you control, the one that operates at the endpoint, monitors execution rather than intent, and functions regardless of whether the model above it is safe, compromised, or simply gone.
That’s what preemptive security means. And Fable 5 just made the case better than we ever could.
Brad Potteiger is the Chief Technology Officer at Arms Cyber, where he leads the development of an AI-native endpoint security solution geared towards protecting against AI agent threats, polymorphic ransomware, and backup data corruption.
References
[1] Anthropic, “Claude Fable 5 and Claude Mythos 5,” June 9, 2026. https://www.anthropic.com/news/claude-fable-5-mythos-5
[2] Anthropic, “Project Glasswing,” April 7, 2026. https://www.anthropic.com/glasswing
[3] CryptoBriefing, “Anthropic disputes jailbreak allegations against Claude Fable 5,” June 2026. https://cryptobriefing.com/anthropic-disputes-claude-fable-5-jailbreak/
[4] Cybersecurity News, “Anthropic’s Claude Fable 5 Jailbroken to Generate Stack Exploits,” June 2026. https://cybersecuritynews.com/anthropics-claude-fable-5-jailbroken/
[5] Cointelegraph, “Researcher Jailbreaks Claude Fable 5 Within 48 Hours of Launch,” June 2026. https://cointelegraph.com/news/researcher-claims-hes-already-jailbroken-anthropics-guardrailed-claude-fable-5
[6] TechTimes, “Claude Fable 5 Hit by Jailbreak Claims and ‘Secret Sabotage’ Backlash Days After Launch,” June 2026. https://www.techtimes.com/articles/318268/20260612/claude-fable-5-hit-jailbreak-claims-secret-sabotage-backlash-days-after-launch.htm
[7] Anthropic, “Statement on the US government directive to suspend access to Fable 5 and Mythos 5,” June 12, 2026. https://www.anthropic.com/news/fable-mythos-access
[8] Picus Security, “What Is Project Glasswing? Anthropic’s AI Misuse Research Initiative Explained,” May 2026. https://www.picussecurity.com/resource/blog/anthropics-project-glasswing-paradox
[9] Help Net Security, “Anthropic: Claude Mythos identified 10,000+ software flaws,” May 26, 2026. https://www.helpnetsecurity.com/2026/05/26/anthropic-project-glasswing-update/
[10] Forrester, “Project Glasswing Shows That AI Will Break The Vulnerability Management Playbook,” 2026. https://www.forrester.com/blogs/project-glasswing-shows-that-ai-will-break-the-vulnerability-management-playbook
[11] TechCrunch, “Anthropic’s Claude Fable 5 is a version of Mythos the public can access today,” June 9, 2026. https://techcrunch.com/2026/06/09/anthropics-claude-fable-5-is-a-version-of-mythos-the-public-can-access-today/
[12] BotCrawl, “Claude Fable 5 Jailbreak Exposes Weakness in Anthropic’s Guardrails,” June 2026. https://botcrawl.com/claude-fable-5-jailbreak/
[13] AY Automate, “Inside the Claude Fable 5 System Prompt: 9 Lessons From the 120K-Character Leak,” June 2026. https://www.ayautomate.com/blog/claude-fable-5-system-prompt-leak
[14] OpSec Insider, “Claude Fable 5 Jailbroken: System Prompt Leaked,” June 2026. https://opsecinsider.com/claude-fable-5-jailbreak/
[15] Gate News, “Claude Fable 5 Breached Within 48 Hours of Release; System Prompt Leaked on GitHub,” June 2026. https://www.gate.com/news/detail/claude-fable-5-breached-within-48-hours-of-release-system-prompt-leaked-on-21803385
[16] VentureBeat, “Anthropic blocks all public access to Claude Fable 5, Mythos 5 following US government order,” June 13, 2026. https://venturebeat.com/technology/anthropic-blocks-all-public-access-to-claude-fable-5-mythos-5-following-us-government-order-what-enterprises-should-do
[17] Fortune, “Anthropic disables Fable and Mythos AI models after U.S. government bars it from giving foreigners access,” June 13, 2026. https://fortune.com/2026/06/13/anthropic-disables-fable-mythos-export-controls-national-security-threat/
[18] ExplainX, “When Will Fable 5 Be Available Again? What We Know,” June 15, 2026. https://explainx.ai/blog/when-will-fable-5-be-available-again-2026
[19] BeInCrypto, “Anthropic Races to Reverse Fable 5, Mythos 5 Export Controls,” June 15, 2026. https://beincrypto.com/anthropic-white-house-fable-mythos-5-access/
[20] The Register, “Feds freaked over Fable 5 after simple ‘fix this code’ prompt, not jailbreak, says researcher,” June 15, 2026. https://www.theregister.com/security/2026/06/15/feds-freaked-over-fable-5-after-simple-fix-this-code-prompt-not-jailbreak-says-researcher/

There’s an arms race happening at the endpoint. EDR products represent a genuine leap forward in enterprise security:...

The same stealth-driven agent that makes ransomware and other attacks irrelevant now closes the visibility gap left by DLP,...

A behavioral baseline is not a product you buy. It is a commitment you make – to understand what your environment actually...

If you only followed the payment data, you might conclude that the ransomware problem is getting better. Average ransom payments...
To connect now, contact: [email protected].